Por razones de trabajo me he encontrado algunas veces con este escenario, y después de haber tenido un par de problemas no muy graves pero que consumían tiempo se me ocurrió un esquema que hasta el momento me funciona, y es lo que voy a compartir en el post.
Minimalismo, si esa es la respuesta a esto, ya que regresamos a lo mas simple al exponer los web services retornando un string siempre como resultado del método, y así mismo recibir datos primitivos como parámetros, reemplazando a la estructuras de datos complejas, pero no en su totalidad ya que en ese dato primitivo en realidad contiene una estructura compleja serializada en Json y comprimida con un algoritomo Zip estándar y convertido a Hexadecimal.
La solución puede ser aplicada no solo a cliente .Net sino también a clientes Java, pero vamos a enfocar el post en clientes .net.
Para el lado del server Java vamos a necesitar los siguientes componentes adicionales al JDK:
- Google Gson (Ya he utilizado esta librería en otros posts, recomendada hasta que el JDK no tenga incluya una implementación estándar de manipulación de Json)
- Apache Commons Codec
Para los clientes de .net van los siguientes componentes adicionales al framework:
- Json.Net
- Si van a ser clientes de compact framework deben utilizar:
- Json for CF
- SharpZipLib de SharpDevelop
Ya con esto listo, creamos un proyecto web en java en su IDE preferido, yo voy a utilizar eclipse.
Para el ejemplo tengo 3 clases; un bean con una propiedad, luego un bean un poco mas complejo y finalmente uno que contiene a todo para mostrar una clase con una estructura no tan simple como prueba de concepto, aquí el código de cada uno:
public class SuperSimpleBean {
private int number;
public SuperSimpleBean(int number){
this.number = number;
}
public SuperSimpleBean(){
}
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
}
public class SimpleBean{
private String code;
private Date datetime;
private List superSimpleBeans;
public SimpleBean(){
superSimpleBeans = new ArrayList();
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public Date getDatetime() {
return datetime;
}
public void setDatetime(Date datetime) {
this.datetime = datetime;
}
public List getSimpleBeans() {
return superSimpleBeans;
}
public void setSimpleBeans(List superSimpleBeans) {
this.superSimpleBeans = superSimpleBeans;
}
}
public class ComplexBean {
private List simpleBeans;
private String name;
public ComplexBean(){
simpleBeans = new ArrayList();
}
public List getSimpleBeans() {
return simpleBeans;
}
public void setSimpleBeans(List simpleBeans) {
this.simpleBeans = simpleBeans;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
El objeto que va a devolver el web service en string va a pasar por los siguientes pasos:
- Serializacion a Json
- Compresion del Json
- Convertir a un String hexadecimal los bytes comprimidos
Las clases que nos van a ayudar con ese cometido son las siguientes:
public class ZipUtil {
private static String toHexString(byte[] bytes) {
return Hex.encodeHexString(bytes);
}
private static byte[] toByteArray(String hexString) {
try {
return Hex.decodeHex(hexString.toCharArray());
} catch (DecoderException e) {
e.printStackTrace();
}
return null;
}
private static byte[] fromGByteToByte(byte[] gbytes) {
ByteArrayOutputStream baos = null;
ByteArrayInputStream bais = new ByteArrayInputStream(gbytes);
try {
baos = new ByteArrayOutputStream();
GZIPInputStream gzis = new GZIPInputStream(bais);
byte[] bytes = new byte[1024];
int len;
while ((len = gzis.read(bytes)) > 0) {
baos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
return (baos.toByteArray());
}
private static byte[] fromByteToGByte(byte[] bytes) {
ByteArrayOutputStream baos = null;
try {
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
baos = new ByteArrayOutputStream();
GZIPOutputStream gzos = new GZIPOutputStream(baos);
byte[] buffer = new byte[1024];
int len;
while ((len = bais.read(buffer)) >= 0) {
gzos.write(buffer, 0, len);
}
gzos.close();
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
return (baos.toByteArray());
}
public static String compressAndEncodeText(String text) {
return toHexString(fromByteToGByte(text.getBytes()));
}
public static String decompressAndDecode(String data) {
data = data.replace("-", "");
byte[] zippedBytes;
try {
zippedBytes = toByteArray(data);
byte[] decompressed = fromGByteToByte(zippedBytes);
return new String(decompressed);
} catch (Exception e) {
e.printStackTrace();
}
return "";
}
}
public class ParserUtil {
public static String parseAndCompress(Object o){
String json = new Gson().toJson(o);
return ZipUtil.compressAndEncodeText(json);
}
}
Y ahora en la clase que se va a exponer como web service creamos objetos dummy con datos y devolvemos el resultado serializado y comprimido:
public class WebService {
public String getData(){
ComplexBean cBean = new ComplexBean();
cBean.setName("A complex bean");
for(int i=0; i<=1000; i++){
SimpleBean sBean = new SimpleBean();
sBean.setCode(String.format("Code %s", i));
sBean.setDatetime(Calendar.getInstance().getTime());
for(int j=0; j<=10;j++){
SuperSimpleBean ssBean = new SuperSimpleBean(j);
sBean.getSimpleBeans().add(ssBean);
}
cBean.getSimpleBeans().add(sBean);
}
return ParserUtil.parseAndCompress(cBean);
}
}
Publicamos el web service, lo probamos con soapUI y el resultado es el siguiente:

1f8b0800000000000000dddcbd8aa4d71586d15b693a9ea0cefe39679fce2c83338……… un string hexadecimal.
Si devolviera json en el web service, el tamaño de los datos de respuesta seria de 216kb, mientras que la respuesta comprimida es de 6.34kb, ustedes pueden calcular el porcentaje de compresión.
Del lado del cliente .net simplemente hay que hacer las clases con la misma estructura, algo que aun no he tenido tiempo para revisar es que al momento de deserializar el json las clases de .net en compact framework deben tener declarados los campos, en lugar de tener propiedades automáticas, honestamente no he encontrado en la librería Json for CF algún parámetro para que sea case insensitive, pero para el framework estándar no hay problemas:
public class SuperSimpleClassInfo
{
public int Number { get; set; }
public SuperSimpleClassInfo()
{
}
public SuperSimpleClassInfo(int number)
{
this.Number = number;
}
}
public class SimpleClassInfo
{
public string Code { get; set; }
public DateTime DateTime { get; set; }
public List<SuperSimpleClassInfo> SuperSimpleBeans { get; set; }
public SimpleClassInfo()
{
SuperSimpleBeans = new List<SuperSimpleClassInfo>();
}
}
public class ComplexClassInfo
{
public string Name { get; set; }
public List<SimpleClassInfo> SimpleBeans { get; set; }
public ComplexClassInfo()
{
SimpleBeans = new List<SimpleClassInfo>();
}
}
Necesitamos una clase para convertir el texto hexadecimal a bytes, descomprimir y luego “parsear” el json a nuestra estructura de objetos, para descomprimir el texto creamos una clase ZipUtil similar a la que tenemos del lado de java:
public class ZipUtil
{
public static byte[] Decompress(byte[] compressed)
{
byte[] buffer = new byte[4096];
using (MemoryStream ms = new MemoryStream(compressed))
using (GZipStream gzs = new GZipStream(ms, CompressionMode.Decompress))
using (MemoryStream uncompressed = new MemoryStream())
{
for (int r = -1; r != 0; r = gzs.Read(buffer, 0, buffer.Length))
if (r > 0) uncompressed.Write(buffer, 0, r);
return uncompressed.ToArray();
}
}
public static byte[] Compress(byte[] raw)
{
using (MemoryStream memory = new MemoryStream())
{
using (GZipStream gzip = new GZipStream(memory, CompressionMode.Compress, true))
{
gzip.Write(raw, 0, raw.Length);
}
return memory.ToArray();
}
}
public static string CompressAndEncode(string text)
{
byte[] compressed = Compress(System.Text.ASCIIEncoding.UTF8.GetBytes(text));
string hex = BitConverter.ToString(compressed);
return hex;
}
public static byte[] ToByteArray(string hexString)
{
hexString = hexString.Replace("-", "");
int NumberChars = hexString.Length;
byte[] bytes = new byte[NumberChars / 2];
for (int i = 0; i < NumberChars; i += 2)
bytes[i / 2] = Convert.ToByte(hexString.Substring(i, 2), 16);
return bytes;
}
public static string DecompressAndDecode(string text)
{
byte[] textBytes = ToByteArray(text);
byte[] uncompressed = Decompress(textBytes);
string result = System.Text.ASCIIEncoding.ASCII
.GetString(uncompressed, 0, uncompressed.Length);
return result;
}
}
Listo, con todo ya preparado agregamos la referencia al web service:
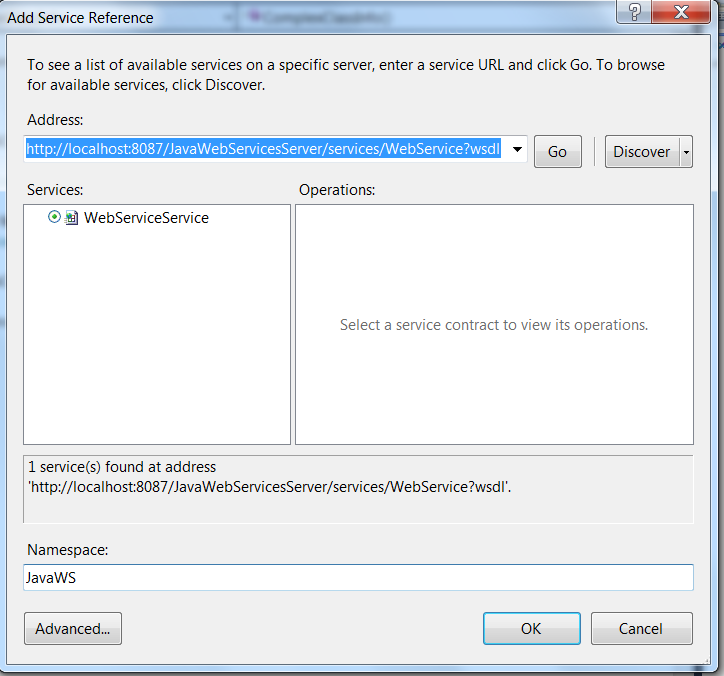
Una vez agregada la referencia es recomendable actualizar en el archivo de configuración el tamaño máximo de datos permitidos en las propiedades: maxBufferSize, maxReceivedMessageSize y maxStringContentLength con el valor 2147483647.
Listo, procedemos a invocar el metodo del web service, a descomprimir y luego con la libreria Json a convertir los datos a un objeto:
JavaWS.WebServiceClient client = new JavaWS.WebServiceClient();
string data = client.getData();
string json = ZipUtil.DecompressAndDecode(data);
ComplexClassInfo complex = JsonConvert.DeserializeObject<ComplexClassInfo>(json);
El resultado es el objeto complex cargado con toda la información para enviar datos en el mismo formato se aplica el proceso inverso desde .net a java.
Happy Coding!
Saludos,
gish@c